
In the realm of large language models (LLMs), techniques like in-context learning (ICL), retrieval augmented generation (RAG), fine-tuning, and retrieval augmented fine-tuning (RAFT) are revolutionizing how these models process information and generate responses. These techniques address key challenges such as scalability, precision, recall, customization, and data quality, significantly enhancing the accuracy and relevance of LLMs across various tasks and domains.
Let’s delve into the intricacies of these methods and their impact on modern language processing capabilities.
Limitations of In-Context Learning
In-context learning (ICL) is a technique used by large language models (LLMs) where the model is provided with a context that includes examples of the task it is supposed to perform. While ICL can be powerful, it has several limitations:
- Scalability: ICL struggles with scalability issues. As the complexity of the tasks increases, the model requires more examples and context, which can become impractical.
- Precision and Recall: The precision and recall in ICL can be inconsistent. This inconsistency arises because the model may not always generalize well from the provided examples.
- Dependency on Examples: The performance of ICL heavily depends on the quality and relevance of the examples provided. If the examples are not well-chosen, the model’s performance can degrade significantly.
Retrieval Augmented Generation (RAG)
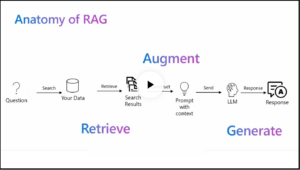
Retrieval Augmented Generation (RAG) is an advanced technique used to enhance the capabilities of LLMs by integrating external knowledge retrieval mechanisms. RAG operates in two primary stages:
- Retrieval: In this stage, the model queries an external knowledge base to retrieve relevant documents or pieces of information based on the input query.
- Generation: In the second stage, the retrieved information is used to generate a coherent and contextually accurate response to the original query.
Issues with Precision and Recall in RAG
- Precision: RAG models might retrieve documents that are not entirely relevant to the query, leading to lower precision.
- Recall: The model might miss out on relevant documents, leading to lower recall. Balancing precision and recall is crucial for the effective performance of RAG systems.
Fine-Tuning Large Language Models
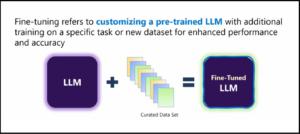
Benefits of Fine-Tuning
- Customization: Fine-tuning allows LLMs to be tailored to specific tasks or domains, enhancing their relevance and accuracy for those applications.
- Improved Performance: Fine-tuned models typically perform better on specific tasks than general-purpose models because they are adapted to the nuances of those tasks.
Challenges of Fine-Tuning
- Data Quality: The quality of the data used for fine-tuning is critical. Poor quality or biased data can negatively impact the model’s performance.
- Computational Resources: Fine-tuning requires significant computational resources, including powerful hardware and extensive training time.
- Expertise: Fine-tuning LLMs effectively requires expertise in machine learning and domain-specific knowledge to select appropriate data and tune hyperparameters.
RAFT (Retrieval Augmented Fine-Tuning)
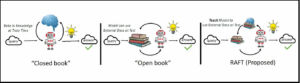
Retrieval Augmented Fine-Tuning (RAFT) is an advanced technique that combines the strengths of retrieval-augmented generation with the benefits of fine-tuning. RAFT involves fine-tuning an LLM using a combination of retrieved external documents and task-specific data.
- Enhanced Accuracy: By leveraging external knowledge, RAFT improves the model’s accuracy and contextual understanding.
- Improved Generalization: RAFT models can generalize better to new queries by incorporating diverse information from external sources during fine-tuning.
Training and Inference Procedures in RAFT
- Training: During training, the model learns to retrieve relevant documents and use them to generate responses. This process involves optimizing both the retrieval mechanism and the generation model simultaneously.
- Inference: At inference time, the model first retrieves relevant documents based on the input query and then generates a response using the retrieved information.
Performance of RAFT Compared to Other Models RAFT models generally outperform standard fine-tuned models and in-context learning approaches in terms of accuracy, relevance, and contextual understanding. The integration of external knowledge sources allows RAFT models to handle a broader range of queries with higher precision and recall.
Preparation and Use of Datasets for Fine-Tuning
Creating Training, Validation, and Evaluation Datasets
- Training Datasets: These datasets are used to train the model. They should be large, diverse, and representative of the tasks the model will perform. Ensuring high-quality and relevant data is crucial.
- Validation Datasets: These datasets are used to tune hyperparameters and prevent overfitting. They help in evaluating the model’s performance during the training process.
- Evaluation Datasets: These datasets are used to assess the final performance of the model after training. They should be distinct from the training and validation datasets to provide an unbiased evaluation of the model’s capabilities.
Proper preparation of these datasets involves data cleaning, annotation, and ensuring diversity and relevance to the target tasks. This process is vital for achieving high performance in fine-tuned models.
In summary, the advancements in language model techniques such as in-context learning (ICL), retrieval augmented generation (RAG), fine-tuning, and retrieval augmented fine-tuning (RAFT) have significantly improved the capabilities of large language models (LLMs). While each technique has its benefits and challenges, collectively they offer a comprehensive toolkit for enhancing the accuracy, relevance, and contextual understanding of LLMs across diverse tasks and domains. The integration of external knowledge sources, fine-tuning for specific tasks, and balancing precision and recall are critical elements in advancing language processing technologies. These techniques pave the way for more sophisticated and effective language models capable of handling complex queries and generating coherent responses with greater accuracy.
Note – The above content is based on a session Practicalities of Fine-Tuning Llama 2 with AI Studio at Build 2024.