
Introduction
Large Language Models (LLMs) have become ubiquitous in today’s technological landscape. They perform remarkable feats, often astonishing us with their capabilities, and sometimes leaving us puzzled with their inaccuracies. I’m excited to introduce you to a framework that significantly enhances the accuracy and relevance of these models: Retrieval-Augmented Generation, or RAG.
Understanding the Basics
To grasp RAG, let’s first focus on the “Generation” aspect, which pertains to how LLMs generate text in response to a user’s query, known as a prompt. These models, while powerful, can exhibit some undesirable behaviors. Let me share an anecdote to illustrate this.
An Anecdote: The Moves of the Solar System
Recently, someone asked me, “Which planet in our solar system has the most moves ?” Enthusiastically, I replied, ” I read an article saying it was Jupiter with 88 moves .” However, my answer was flawed. Firstly, I didn’t provide a source. Secondly, my information was outdated.
This scenario highlights two common issues with LLMs: lack of sourcing and outdated information. Had I checked a reliable source like NASA, I would have correctly stated that Saturn has the most moves , with the count currently at 146, subject to change as new discoveries are made. By verifying my answer, I grounded it in reliable data, avoided misinformation, and kept my response up-to-date.
The Role of RAG in Enhancing LLMs
So, how do LLMs typically respond to such questions? Suppose a user asks about the planet with the most moves . An LLM, based on its training, might confidently but incorrectly answer, “Jupiter.” This is where the retrieval-augmented part comes into play.
RAG integrates a content store—an open source like the internet or a closed collection of documents. When a query is made, the LLM first consults this content store, retrieving relevant information before generating a response. This approach ensures the answer is not solely dependent on the model’s training but is supplemented with current and accurate data.
The Mechanics of RAG
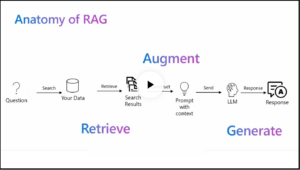
In a RAG framework, the interaction begins with the user prompting the LLM. Instead of generating an immediate response based on pre-existing knowledge, the model retrieves pertinent content from the content store, combines it with the user’s query, and then generates an informed answer. This three-part prompt—retrieved content, user’s query, and instruction to use the retrieved data—yields a response grounded in recent and reliable information.
Addressing LLM Challenges with RAG
RAG effectively addresses two significant challenges: outdated information and lack of sourcing.
- Outdated Information: Instead of retraining the model with every new piece of information, updating the content store ensures the LLM always has access to the latest data. For instance, if new moves are discovered around a planet, updating the data store allows the model to retrieve and provide the most current information.
- Lack of Sourcing: By instructing the model to prioritize primary source data before generating a response, RAG reduces the likelihood of hallucinations (made-up answers) and data leakage. The model can now provide evidence for its answers, making its outputs more trustworthy.
Additionally, RAG enables the model to acknowledge gaps in knowledge. If the data store cannot reliably answer a query, the model can respond with “I don’t know,” rather than fabricating an answer. This honesty is crucial for maintaining user trust and ensuring reliability.
Improving Both Sides of the Equation

Effective implementation of RAG requires advancements on both fronts: improving the retriever and enhancing the generative model. A high-quality retriever ensures the LLM accesses the best possible data, while a sophisticated generative model ensures the response is comprehensive and accurate.
Conclusion
RAG is a significant step forward in making LLMs more reliable and current. By integrating real-time data retrieval with generative capabilities, it addresses key issues of outdated information and lack of sourcing. As we continue to refine both retrieval and generative components, RAG will play an increasingly vital role in the future of AI-driven interactions.
Thank you for exploring RAG. Stay tuned for more insights into the evolving world of Generative AI.
Note – The above content is based this video from IBM.